The LiteSpeed Cache Crawler Script¶
Cache Warmup¶
The crawler travels through your site, refreshing pages that have expired in the cache. This makes it less likely that your visitors will encounter un-cached pages.
Before You Begin¶
- Install and enable LSCache for PrestaShop
- Crawler Engin: The crawler must be enabled at the server level, or you will see the warning message
Server crawler engine not enabled. Please check..... If you are using a shared hosting server, please contact your hosting provider, or see our instructions. - SiteMap: Prepare your site's sitemap, e.g.
http://example.com/sitemap.xml. You can use Google, SiteMap, or do it yourself. It doesn't matter how you generate a sitemap, just as long as it is an XML sitemap.
How to Generate a Sitemap¶
Google Sitemap Module¶
Google Sitemap Module is installed by default in both v1.6 and v1.7+.
Navigate to Modules > Module Manager, type the keyword Google sitemap, and click the Configure button. Check Sitemap and click the GENERATE SITEMAP button. You will see your main SITE-MAP-URL, and it should look something like xxx/1_index_sitemap.xml.
SiteMap Online Generator¶
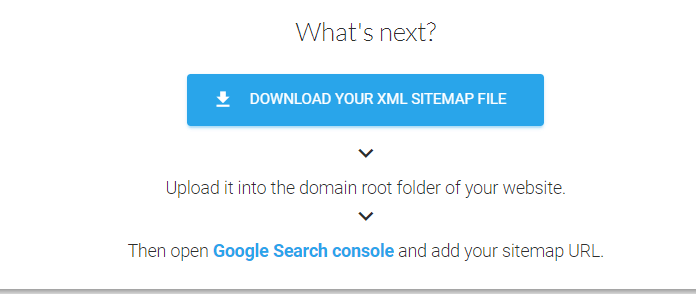
One of the popular sitemap generators is XML-Sitemaps.com After the crawl is finished. Click DOWNLOAD YOUR XML SITEMAP FILE and put it where the crawler script can access it.
How to Use the LSCache Crawler Script¶
Change the permissions so that the file is executable: chmod +x cachecrawler.sh
To crawl when desktop & mobile share the same theme: bash cachecrawler.sh SITE-MAP-URL
TO crawl when desktop & mobile have different themes: bash cachecrawler.sh SITE-MAP-URL -m
By default, in the PrestaShop cache plugin, Mobile View is DISABLED. To enable mobile view, navigate to PrestaShop Admin > LiteSpeed Cache > Configuration and set Separate Mobile View to Yes 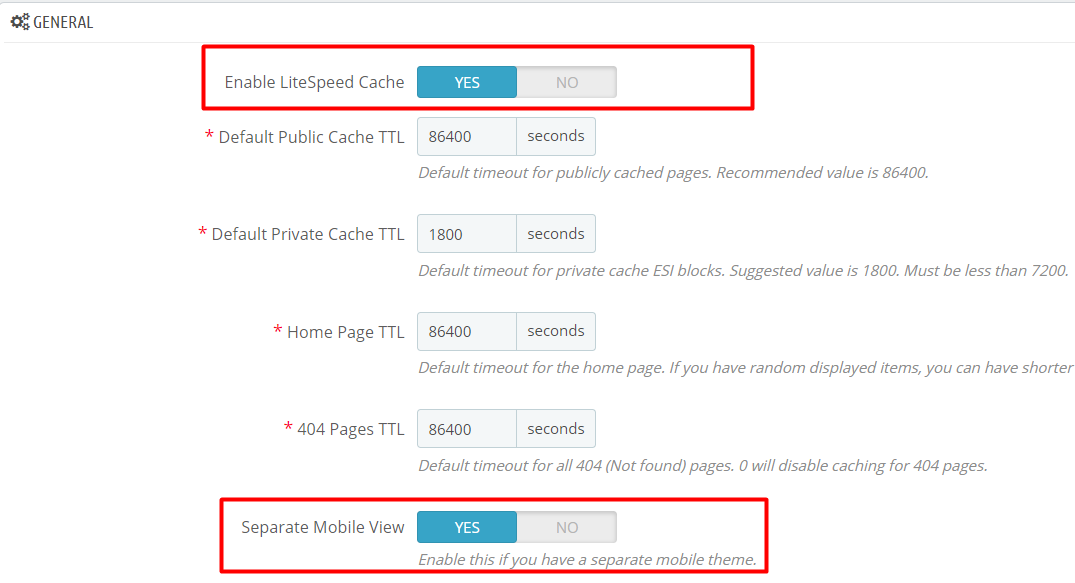
More Options¶
-h, --help: Show this message and exit.-m, --with-mobile: Crawl mobile view in addition to default view.-c, --with-cookie: Crawl with site's cookies.-cc, --custom-cookie: Crawl with site's cookies and custom cookie.-w, --webp: Crawl with webp header-b, --black-list: Page will be added to blacklist if HTML status error and no cache. Next run will bypass page.-g, --general-ua: Use general user-agent instead of lscache_runner for desktop view.-i, --interval: Change request interval.-i 0.2changes from default 0.1 second to 0.2 seconds.-e, --escape: To escape URL with perl, use this when your URL has special character.-v, --verbose: Show complete response header under/tmp/crawler.log.-d, --debug-url: Test one URL directly. as insh M2-crawler.sh -v -d http://example.com/test.html.-qs,--crawl-qs: Crawl sitemap, including URLS with query strings.-r, --report: Display total count of crawl result.
Example commands
- To get help: `bash cachecrawler.sh -h`
- To change default interval request from 0.1s to custom NUM value: `bash cachecrawler.sh SITE-MAP-URL -i NUM`
- To crawl with cookie set: `bash cachecrawler.sh -c SITE-MAP-URL`
- To store log in `/tmp/crawler.log`: `bash cachecrawler.sh -v SITE-MAP-URL`
- To debug one URL and output on screen: `bash cachecrawler.sh -d SITE-URL`
- To display total count of crawl result: `bash cachecrawler.sh -r SITE-MAP-URL`
Tip
Using multiple parameters at the same time is allowed
Crawl Interval¶
How often do you want to re-initiate the crawling process? This depends on how long it takes to crawl your site and what you have set for Public Cache TTL. Default TTL is one day (24 hours). You might consider running the script by cronjob every 12 hours. E.g. This will run twice a day, at 3:30/15:30: 30 3/15 * * * path_to_script/cachecrawler.sh SITE-MAP-URL -m -i 0.2
Tip
You can use an [online crontab tool](https://crontab.guru/) help you to verify time settings.
How to Verify the Crawler is Working¶
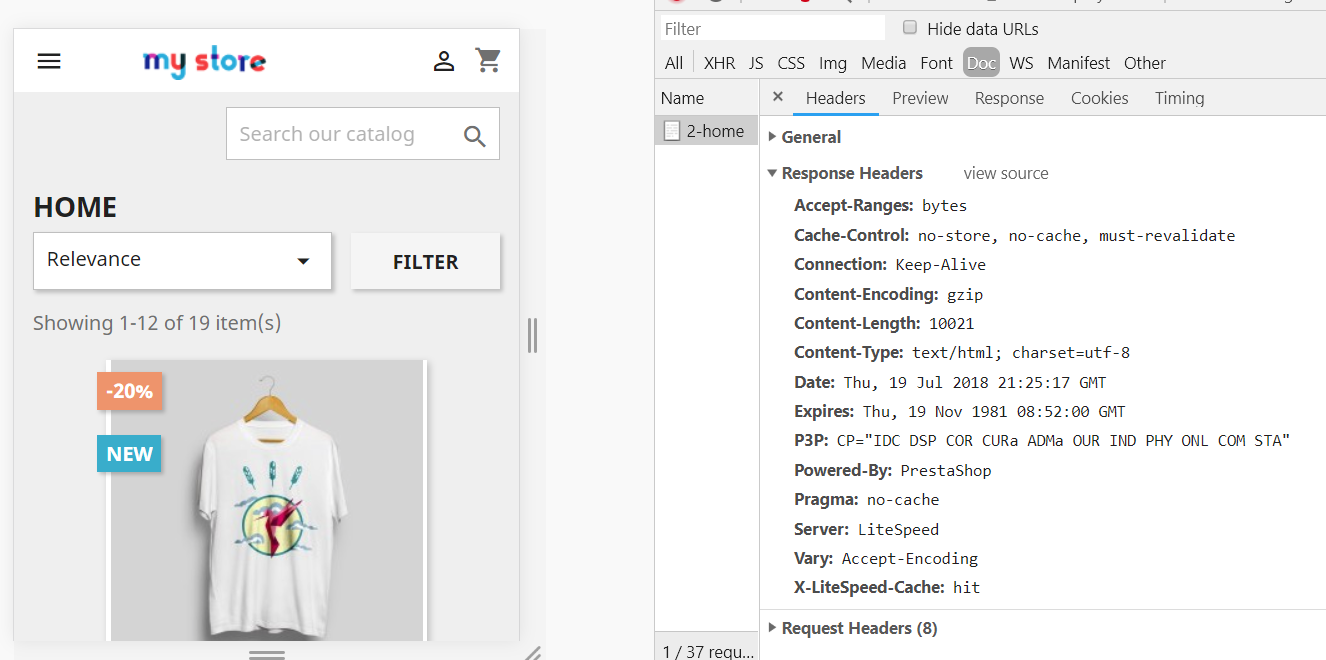
Use the browser developer tool, to look for the X-LiteSpeed-Cache: hit header on the first page view for both desktop and Mobile. If the page has been crawled, it will be a hit.
Desktop view
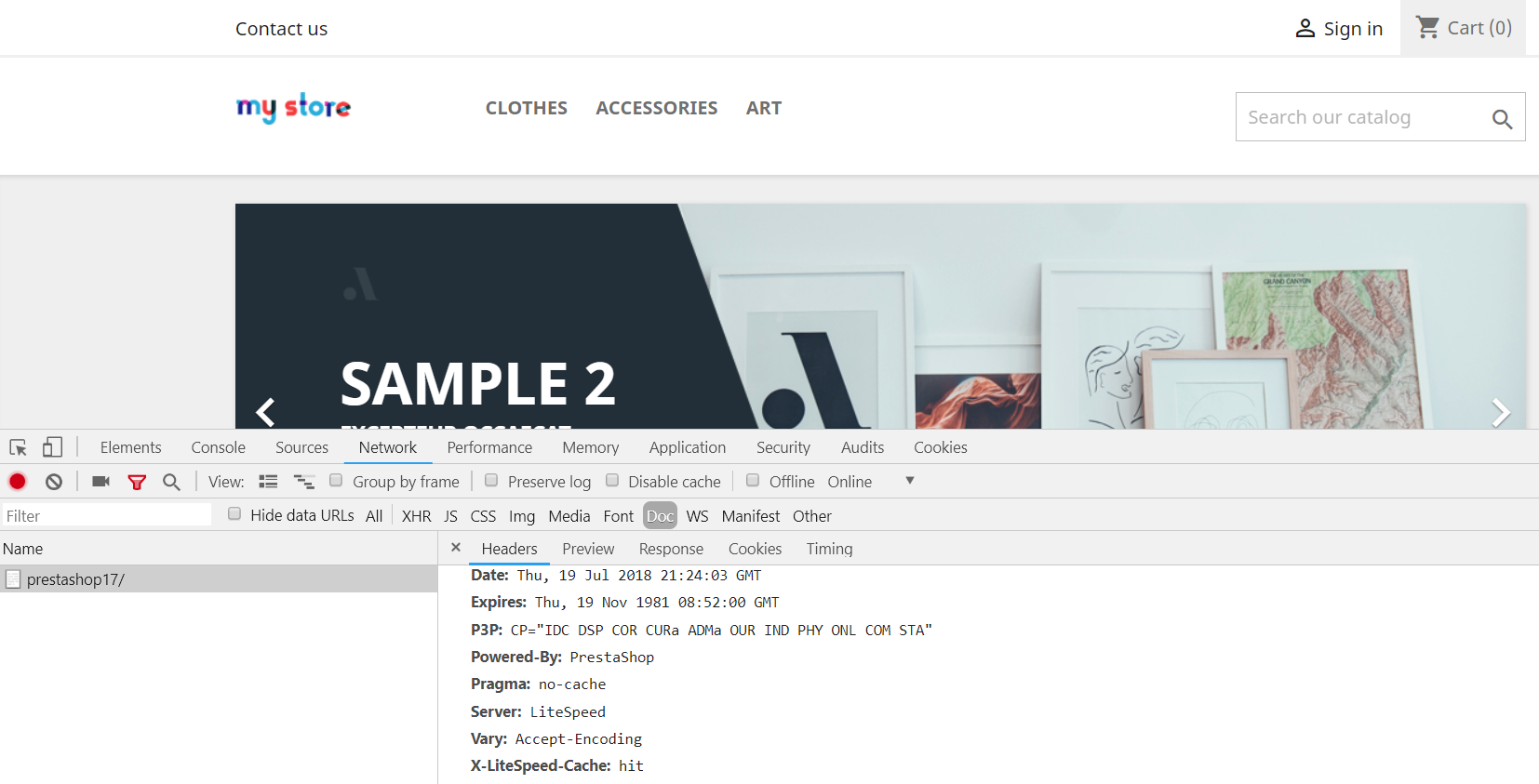
Mobile view